Notes on Writing High-Performance Code
Geoff Carpenter, FARGOS Development, LLCThere are certain classes of applications where performance is not merely a nice-to-have. For example, some automated trading applications rely on speed alone for success; failure to react quickly enough yields actual losses rather than the hoped-for profit. Examples from the life-or-death arena are embedded applications that react to real-world activity, such as the electronic stability controls on an automobile, targeting systems for antimissile batteries, or fly-by-wire controls for aircraft which are inherently unstable in the quest for greater maneuverability. While not of the same level of importance, the quality of a video game is often judged by its frame rate: too slow a frame rate will be viewed as unacceptable for games intended to immediately react to user input (e.g., first person shooters). As more features were added to C++, so increased the availability of mechanisms for the overly-eager programmer to generate code that was difficult to debug or maintain and incurred invisible overhead.
Deleting Null Pointers
It is not uncommon to encounter C++ code written with a construct similar to:
if(p != 0) delete p;or
if (p != nullptr) delete p;
This conservative code is perfectly reasonable; after all, running destructors using a null this pointer and passing a null pointer to free() would cause grief. But, the C++ standard explicitly permits deletion of a null pointer, which means that the runtime itself has to check for the possibility of null pointer. If the application programmer performs the same check, then redundant work is performed when the pointer was not null. The optimal equivalent would be simply:
delete p;
On the other hand, if you have code similar to:
if(p != null) {
// do something
delete p;
}
there is no reason to move the delete outside of the control of the if-statement as this would result in the test for a null pointer being performed twice on those occasions when the pointer is in fact null.
Templates
C++ templates are a great addition to the language, but their expressive power is Turing-complete. Once upon a time, I wrote the trivial CRAP compiler (an acronym for Complex Recursive Algorithmic Programs) for implementing Turing machine program homework assignments and the name illuminates some of the issues involved. One can perform functional programming at compile-time via recursive invocations of templates, which tends to be non-obvious to most developers due to its complex and recursive nature. Like an exotic sports car, templates can get away from the over-confident user but they certainly are attractive. Prior to the introduction of templates into C++, I observed that most programmers who were attempting to make effective use of C++ would think about not only the separation between the data and executable implementation details, but also the commonality between elements in an attempt to discern what could be suitably modeled using a base class and which specializations should be implemented using derived classes that inherited from those base classes.
After templates became available, I have seen many newly-minted programmers expend their effort on writing templates without ever thinking about the common aspects and how to model their objects appropriately. Their approach was to implement a standalone class described by a template and their application code was written to assume allomorphic interfaces rather make use of a single implementation that was obtained via inheritance and shared amongst several classes. While they wrote the code only "once" in the form of a template, the compiler actually rewrote it many times for each distinct set of template arguments. Nothing good is yielded from such unfocused bloat. At a minimum, this approach destroys the usefulness of the CPU's instruction cache by bloating the text segment with uniquely-named functions whose implementation logic is identical. When done optimally, a single instance of an implementation of a routine will exist in a base class, which yields a smaller text segment and more efficient use of the instruction cache. Specialization would be done via inheritance and virtual functions. When done wrong, the same sequence of instructions get generated by the compiler over and over for uniquely named functions and dynamic_cast gets used for special-case handling. Even worse, programmers may resort to exploiting runtime type information to determine the proper way to access an object.
Best results are obtained by first implementing an appropriate class hierarchy with templates providing an avenue for injecting specificity into a generic implementation.
Templates are also ideal for computing somewhat complicated results
at compile-time. Compilers have long been able to able to do constant
folding for simple integer math, like reducing 2 + 3
to 5, but were not inclined to do more complicated calculations.
Templates are sometimes very useful for calculating values at compile-time,
this this example that computes a power-of-10.
template <unsigned int EXPONENT> inline CONSTEXPR uint64_t powerOf10Constant()
{
return (powerOf10Constant < EXPONENT - 1 > () * 10);
}
// specialization of powerOf10Constant<>() to stop recursion at 0
template <> inline CONSTEXPR uint64_t powerOf10Constant<0>()
{
return (static_cast(1));
}
C++ Exceptions
C++ exceptions were approved for the 1998 ISO standard. Some developers became enamored with them, while others recognized that portions were poorly done from the beginning and the cost can be insidious if not used with care. The annotation of functions with exception specifications is an example of something that just does not work as most people expect and ultimately would be charitably described as useless. Essentially, the specification requires the compiler to enforce at runtime what exceptions can be thrown. This article from 2002 covers most of the ground: http://www.gotw.ca/publications/mill22.htm.
Out Of Memory Conditions
Older code which attempted to handle out-of-memory conditions contains constructs like:
p = new SomethingInteresting();
if (p == nullptr) {
// handle out-of-memory condition
}
If you encounter code like this, you are seeing something that now represents wishful thinking and, as written, is just wasted overhead as the if-statement will be evaluated upon every successful invocation of the new operator but will never be utilized if an actual out-of-memory condition occurs. The 1998 standard changed the behavior of the default new operator to throw exceptions under conditions which had previously caused a null pointer to be returned, rendering all of that attempted error handling code useless. The nothrow variant of the new operator has to be used in order to obtain the original behavior:
p = new(std::nothrow) SomethingInteresting();
if (p == nullptr) {
// handle out-of-memory condition
}
Most operating systems will cause a program to die if a null pointer is referenced, but IBM's AIX stands out as one of those that made the abysmal decision to allow null pointers to be dereferenced without error in the name of "compatibility". On platforms with this idiosyncrasy, not crashing is not a proof of correctness. At best, this should have been permitted using an environment variable option examined at the time the process is originally invoked or (preferably) by linking against a special runtime library that allocated page 0 before invoking main(), but programmers have suffered on that platform for over a decade due to that ill-advised decision. Developers writing portable code use other platforms as a primary target and port to AIX rather than from AIX due to both decisions like that and documentation which fails to identify the provenance of kernel and library APIs. Unfortunately, proving that all of the out-of-memory error conditions are appropriately handled in a codebase can be a challenge. Consider the difficulty of triggering an out-of-memory condition for the second allocation while the first succeeds:
p1 = new(std::nothrow) SomethingInteresting();
if (p1 == nullptr) {
// handle first out-of-memory condition
}
// allocate a second object
p2 = new(std::nothrow) SomethingElse();
if (p2 == nullptr) {
// handle second out-of-memory condition
}
Most code is too complex and the objects too small to allow individual statements to be targeted in test scenarios unless the memory allocation routine is overridden with a variant that returns an out-of-memory indication after a certain number of allocations. That technique can also be used with code that makes use of exceptions. Given that the common scenario was to have a program crash after attempting to deference a null pointer, the 1998 C++ standard took the viewpoint that there is not a great deal of difference if an exception is thrown and the program dies more gracefully via std::terminate() if no application-specific try blocks are in scope. As noted, it did render useless any code that attempted to handle out-of-memory errors. Such code needs to be modified to either use the nothrow variant of the new operator or be completely modified to use try/catch blocks.
Which is the best approach? Ultimately, the right answer depends on the compiler and the amount of time that one can devote to reengineering. If your compiler has a significant overhead for a try block, you might be better off with the nothrow variant of the new operator, but it still will not be free. Because of the semantics of the nothrow specification, the C++ compiler has to emit barrier code to prevent any exception from being propagated. This overhead means that the invocation of the default new operator is cheaper than the nothrow variant. If your compiler is able to implement try blocks with essentially zero overhead, then you are in the fortunate position that you will have less overhead than before because the barrier code is not generated. You also benefit from the elimination of the almost-always-fails test for a null pointer in the if-statement after the new operator.
try {
p = new SomethingInteresting();
}
catch(...) {
// handle out-of-memory condition
}
For portable and generic code intended to be compiled by a variety of compilers, the best approach is to use the default new operator and rework any existing tests for a null pointer into an appropriate try and catch block pair rather than modify code to use the nothrow variant.
Failed Constructors
The new operator really works in multiple phases: it dynamically allocates memory and executes the appropriate constructors for base and derived classes. The code for a constructor can be arbitrarily complex and may need to dynamically allocate memory of its own and fail or attempt an action that cannot be performed (like create a file). Throwing an exception is the mechanism intended to be used to indicate an object failed to be constructed appropriately, which could be for a reasons other than just a lack of free memory and are the usual example for illustration why exceptions were deemed necessary for C++. If you do throw an exception from a constructor, do not assume that that everything gets cleaned up flawlessly: your constructor is responsible for cleaning up what it allocated prior to the exception being thrown. While the destructors for any bases classes which have been constructed will be invoked, the destructor for the class in question will not, so cleanup cannot be deferred. See Appendix E of the third edition of The C++ Programming Language for a detailed discussion.
Exception Overhead
Where else should exceptions be used rather than returning a conventional error indication? If you are writing code intended to be called from other languages, such as C, you will minimize the disparity between the native API and the foreign language API if you avoid features that are unsupported by the caller as well. The official API could be common to all simply by declaring a routine extern "C" and using C-only data structures and conventions, thus eliminating the requirement for a glue layer. For other scenarios, if you have the luxury of writing code that is to be compiled by a known set of compilers and you understand the nature of the code they generate, then you can afford to be less cautious. If you do not know the set of compilers that will process your code base, then you should probably be aware of the worst-case scenarios.
This web-based article discusses how Microsoft Visual C++ implemented support for exception handling: http://www.codeproject.com/Articles/2126/How-a-C-compiler-implements-exception-handling. The overhead introduced by that implementation approach has a notable cost, as discussed by this article regarding the optimization of the Xbox game MechAssault 2: http://www.gamearchitect.net/Articles/CompilerOptimizationOfMA2.html. Note that the Xbox had what was essentially a Pentium III CPU in contrast to the PowerPC-based consoles that succeeded it (i.e., Xbox 360, Playstation 3 and Nintendo Wii), so Windows-like development tools were commonly used for game development targetting that platform. The crucial point is that try blocks were not free with that implementation approach and one should be aware that some mainstream compilers have implemented them using methods that incur measurable overhead.
In fairness, the runtime overhead for a try block does not have to be that expensive and the current g++ implementation for x86_64 serves as a prime example. It was guided by the ABI designed for Intel's Itanium CPU: http://sourcery.mentor.com/public/cxx-abi/abi-eh.html.
The assembler output of two nearly identical functions is presented in Figure 1 to illustrate the extra code generated by g++ for a simple try/catch block. It is important to note that the code associated with the catch block does not appear intermixed with the normal instruction flow. When compared side-by-side, it is easy to see that the generated instructions are nearly identical. The try block incurs the overhead of another 16 bytes on the stack. While it makes no difference in the execution time of the sub instruction adjusting the stack pointer, the extra stack space utilized does consume 25% of a 64-byte cache line. That is unfortunate, but high praise must be given to the implementation approach which otherwise has effectively zero impact if no exception is thrown. The cost of throwing an exception, however, is another story.
Figure 1 Example g++ implementation of exception handler for x64
|
Function plain1(char const*) |
Function except1(char const*) |
int plain1(const char *mess)
{
C1 *c;
c = new C1(mess);
return (c->value())
}
|
int except1(const char *mess)
{
C1 *c;
try {
c = new C1(mess);
}
catch (const char *mess) {
std::cerr << "throw mess: " << mess << std::endl;
}
catch (int rc) {
std::cerr << "throw rc: " << rc << std::endl;
}
return (c->value());
}
|
400ac4 <+0>: push %rbp
400ac5 <+1>: mov %rsp,%rbp
400ac8 <+4>: push %rbx
400ac9 <+5>: sub $0x28,%rsp
400acd <+9>: mov %rdi,-0x28(%rbp)
400ad1 <+13>: mov $0x40,%edi
400ad6 <+18>: callq 0x4009c0
400adb <+23>: mov %rax,%rbx
400ade <+26>: mov -0x28(%rbp),%rax
400ae2 <+30>: mov %rax,%rsi
400ae5 <+33>: mov %rbx,%rdi
400ae8 <+36>: callq 0x400cd6
400aed <+41>: mov %rbx,-0x18(%rbp)
400af1 <+45>: mov -0x18(%rbp),%rax
400af5 <+49>: mov %rax,%rdi
400af8 <+52>: callq 0x400d00
400afd <+57>: add $0x28,%rsp
400b01 <+61>: pop %rbx
400b02 <+62>: pop %rbp
400b03 <+63>: retq
End of assembler dump.
|
400b04 <+0>: push %rbp
400b05 <+1>: mov %rsp,%rbp
400b08 <+4>: push %rbx
400b09 <+5>: sub $0x38,%rsp
400b0d <+9>: mov %rdi,-0x38(%rbp)
400b11 <+13>: mov $0x40,%edi
400b16 <+18>: callq 0x4009c0
400b1b <+23>: mov %rax,%rbx
400b1e <+26>: mov -0x38(%rbp),%rax
400b22 <+30>: mov %rax,%rsi
400b25 <+33>: mov %rbx,%rdi
400b28 <+36>: callq 0x400cd6
400b2d <+41>: mov %rbx,-0x18(%rbp)
400b31 <+45>: mov -0x18(%rbp),%rax
400b35 <+49>: mov %rax,%rdi
400b38 <+52>: callq 0x400d00
400b3d <+57>: add $0x38,%rsp
400b41 <+61>: pop %rbx
400b42 <+62>: pop %rbp
400b43 <+63>: retq
400b44 <+64>: mov %rax,%rbx
400b47 <+67>: callq 0x400980
400b4c <+72>: mov %rbx,%rax
400b4f <+75>: mov %rax,%rdi
400b52 <+78>: callq 0x4009d0
400b57 <+83>: mov %rax,%rbx
400b5a <+86>: callq 0x400980
400b5f <+91>: mov %rbx,%rax
400b62 <+94>: mov %rax,%rdi
400b65 <+97>: callq 0x4009d0
400b6a <+102>: cmp $0x1,%rdx
400b6e <+106>: je 0x400b7e
400b70 <+108>: cmp $0x2,%rdx
400b74 <+112>: je 0x400bbf
400b76 <+114>: mov %rax,%rdi
400b79 <+117>: callq 0x4009d0
400b7e <+122>: mov %rax,%rdi
400b81 <+125>: callq 0x4009a0
400b86 <+130>: mov %rax,-0x20(%rbp)
400b8a <+134>: mov $0x400e18,%esi
400b8f <+139>: mov $0x601300,%edi
400b94 <+144>: callq 0x400950
400b99 <+149>: mov -0x20(%rbp),%rdx
400b9d <+153>: mov %rdx,%rsi
400ba0 <+156>: mov %rax,%rdi
400ba3 <+159>: callq 0x400950
400ba8 <+164>: mov $0x400990,%esi
400bad <+169>: mov %rax,%rdi
400bb0 <+172>: callq 0x400960
400bb5 <+177>: callq 0x400980
400bba <+182>: jmpq 0x400b31
400bbf <+187>: mov %rax,%rdi
400bc2 <+190>: callq 0x4009a0
400bc7 <+195>: mov (%rax),%eax
400bc9 <+197>: mov %eax,-0x24(%rbp)
400bcc <+200>: mov $0x400e25,%esi
400bd1 <+205>: mov $0x601300,%edi
400bd6 <+210>: callq 0x400950
400bdb <+215>: mov -0x24(%rbp),%edx
400bde <+218>: mov %edx,%esi
400be0 <+220>: mov %rax,%rdi
400be3 <+223>: callq 0x400900
400be8 <+228>: mov $0x400990,%esi
400bed <+233>: mov %rax,%rdi
400bf0 <+236>: callq 0x400960
400bf5 <+241>: callq 0x400980
400bfa <+246>: jmpq 0x400b31
End of assembler dump.
|
Some claim that the overhead of throwing an exception is no more than a function call. In general, this is not even close to being true. The special case of a throw and corresponding catch being within the same function body does provide sufficient information to predetermine the code paths to be executed (and an inlined called routine can count as being within the same function body), but assuming the existence of an optimizer clever enough to figure it out is a bad bet. When an exception is generated by a throw statement, the stack must be unwound to the first catch block that matches the type of the expression being thrown. The mechanism to do this is compiler-specific, but there are at least a couple of things that must occur:
- The stack frames representing the scope of each block will need to be traversed, starting from the currently active scope working upwards, looking for frames associated with a try block.
- The list of catch blocks associated with a try block must be searched to see if there is a match for the type of the expression being thrown. The effort involved here will typically be proportional to the number of catch blocks. This could be done by searching a table generated by the compiler corresponding to the try block or invoking a custom routine associated with the try block that performs the equivalent of a switch statement on expression type id.
The Itanium ABI previously referenced defines a two-phase process in which the appropriate target catch block is first located (the search phrase) and then the stack is traversed once again revisiting the intermediate frames in a cleanup phase which ultimately executes the statements associated with the catch block. This two-phased approach is not mandated by the C++ specification, but it is used to allow intermixing of routines written in languages that do require such flexibility. So, how expensive is the catch processing?
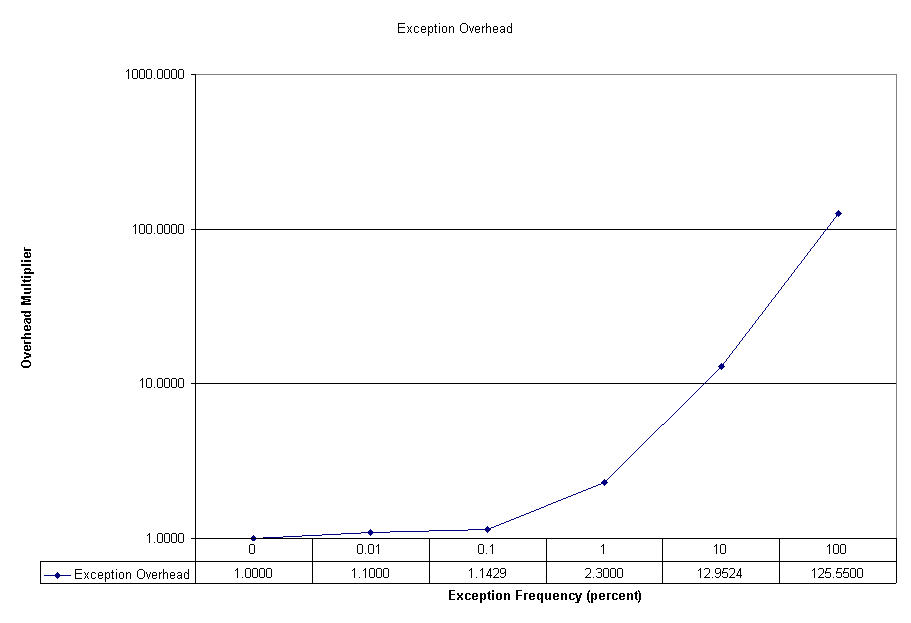
Measurements with g++ on x86_64 indicate that the overhead of a throw-and-catch is 2 orders of magnitude greater than that of a conventional return from a function. If your routine throws an exception more than 1 time in 10000, then you will notice degraded performance vs. a conventional return from the function. More frequently than that? The impact will be worse, heading towards greater than 125 times more overhead than a normal return (the disparity in performance is even greater with optimized code as the overhead in the normal return case is reduced).
Another negative is that while overhead in the conventional return case remains constant regardless of whether or not an error condition is being indicated, the massive overhead of catching an exception will impose a huge variance in performance. If an application encounters a chronic error condition, the impact of repeatedly throwing exceptions can bring the system throughput to a halt and introduce performance failures.
The conclusion to be drawn is that processing of an exception is extremely expensive compared to a conventional approach of returning an error indication. Exceptions should be used for rare, truly exceptional conditions rather than as a mechanism to report common conditions. There are those who are proponents of using exceptions for what should be one-time-only conditions, like searching a collection for an item of interest and adding it if it was not found. As an illustration, the conventional approach would be similar to:
Object *o = findObject(arg);
if (o == nullptr) {
o = addObject(arg);
}
// do something useful with o
Proponents of using exceptions would note that the
if-statement is only productive once for a given argument and
is wasted effort on subsequent invocations. They argue it would be better and
more clear if the code was written:
Object *o;
try {
o = findObjectOrThrow(arg); // now throws an exception rather than return null pointer
}
catch (...) {
o = addObject(arg);
}
// do something useful with o
The clarity argument is doubtful: a reader of the code has to look elsewhere to find the appropriate catch block, which interferes with comprehension of the code. On the positive front, if one's compiler generates a near-zero overhead implementation like the one currently used by g++, then the elimination of the evaluation of the if-statement should disappear with the possibility of some net gain. If, however, the compiler implementation in use does incur some overhead when supporting try blocks, this will be chronically detrimental to performance.
The other factor to consider is that modern hardware supports super-scalar execution and branch prediction tables: even if there is a test for a null pointer present, it may effectively have zero impact on the execution speed and thus eliminating the test from the source code through the use of an exception has no useful effect. I have seen such re-engineering performed on perfectly fine code by developers attempting to demonstrate their "superior" C++ skills, but the result was code which was not faster, ended up with more source code lines, and contributed nothing to the effort of delivering the components needed by the firm.
Always measure before you undertake a rework of pre-existing correct code or embark on a new coding style.
Catch What You Throw
In 1968, Edsger Dijkstra wrote his famous "go to statement considered harmful" letter which was published in the Communications of the ACM. Decades later, exceptions introduce the opportunity for nondeterministic gotos. If your code throws an exception that you do not catch, then it is going to cause a branch to a location of which you are unaware. Few users are going to find this to be a friendly act that contributes to the robustness of their application. If you absolutely have to throw an exception as part of the interface you are providing the user, be very clear in your documentation that the function in question behaves this way. While you might consider it useful to annotate the declaration of the function using an exception specification and most human readers of the source code will view that as an indication that the function will throw an exception, the true semantics are that it forces the compiler to create a barrier that only permits the named exceptions to pass. In contrast, documentation creates no runtime overhead and allows one to be extremely clear.
Trees vs. Hash Tables
Programmers are expected to be conversant with the idea that a lookup on a balanced tree should be an operation of order log base 2 of N (i.e., O(log N)). In contrast, a hash table lookup is supposed to be a constant-time operation (i.e., O(1)). Thus many will assert that hash tables are a superior implementation choice over a balanced tree. In practical terms, this can mean using a std::unordered_map in preference to std::map.
Do not assume that a hash table is better than a balanced tree or a dense sorted array against which one can perform a binary search. Measure and verify which approach performs best on your data. If you use a typedef to define the implementation type in a header, you will only need to touch one line to choose an alternate approach.
While it is true that the overhead of a properly tuned hash table is expected to be constant, constant does not necessarily correspond to fast. Be aware of the following issues:
- The hash function is normally not free and this cost will be paid on every lookup and insertion. The exceptions are trivial cases, such as very small integer types, such as a character or 16-bit integer. Longer integer types are also reasonably cheap, but still require some bit manipulation to collapse them small enough to serve as a bucket subscript. In the frequently occurring case of an array of bytes, the hash requires visiting every byte of the key. For the default hash algorithm implemented in the GNU libsupc++ (e.g., http://c-cpp.r3dcode.com/files/gcc/4/6.2/libstdc++-v3/libsupc++/hash_bytes.cc), the best behavior can be obtained if the key length is exactly a multiple of the sizeof(size_t), but it still involves a loop to retrieve the all of the bytes of the string, as well as perform shifts, multiplications, exclusive ORs, etc. Note: if at all possible, pad the key to be hashed so that its length is a multiple of sizeof(size_t), as it eliminates much of the pathological cases. If a fixed choice common across all architectures needs to be made, pad to a multiple of 8 bytes as this will be suitable for both 32-bit and 64-bit architectures.
- Constant time lookups are only achieved if hashes do not collide to the same bucket. If there is a collision, the overhead of searching the corresponding chain becomes linear. The normal mechanism to avoid collisions is to have a sufficient number of buckets with the bucket identified by the value of the hash mod bucketTotal (which has been one of the more expensive CPU operations historically), but having the optimal number of total buckets is problematic in general. Ideally, the total number of buckets is equal to the number of distinct keys, so there are no wasted buckets and every bucket chain is always of length 1 or less. If the hash function does not generate a sufficiently even distribution of values for the set of keys used by the application, there will be either be a lot of memory wasted by unused buckets or a chain with several entries or both.
- Some applications are deployed in a domain where it is possible to know the set of keys that will be encountered and efforts can be made to pre-tune the hash algorithm and table parameters; however, many applications will not have this luxury and the set of keys seen may evolve over time. If an application cannot pretune the appropriate settings for a hash table, the implementation may attempt to dynamically adjust itself when the load factor increases to a certain level, but this reconfiguration effort will incur an unexpected delay in the middle of processing. This can be fatal if the application has critical latency constraints.
Trees have very good scaling properties and the degradation of performance is well-behaved as the number of elements increases. They avoid the pathological cases that can occur due to an unfortunate combination of keys and hash algorithm. Perhaps most importantly, they do not have the potential for a catastrophic tipping point where performance falls off a cliff.
The default hash on 64-bit architectures will use over 30 integer operations for a 7 byte string and 2 conditional jumps; it will drop to around 16 integer operations for a string of length 8 but still require 2 conditional jumps. Add another 8 operations and 1 conditional jump for each extra set of 8 bytes of length. That is a nontrivial amount of work just to get the hash, constant though it may be, and the search for the desired element has not even begun. That effort could have been redirected towards traversing a tree to locate the desired element, which would have been found already for smaller values of N.
Do not allow assumptions to commit your implementation to a particular algorithm or data structure design. Always measure and validate that your application's performance is appropriate for your environment.